随着大模型技术规模化落地,AI应用的实时性正成为企业竞争力的核心。然而,在算力持续升级的同时,模型从存储层加载至计算单元的环节却日渐成为制约系统效率与弹性的关键瓶颈。缓慢或波动的加载过程,不仅会导致昂贵算力资源的闲置,更直接影响业务响应质量。由此可见,构建高效、稳定的数据供给通道,已成为AI基础设施演进的关键方向。
为验证企业级SSD在真实AI场景中的表现,忆联选择Ollama这一广泛应用的开源大模型部署平台进行深度测试。Ollama不仅能够模拟典型的企业级AI工作负载,如多模型快速加载、高频迭代等,其标准化的调用接口还可精准反映底层存储性能对模型准备时间的实际影响,为存储能力评估提供了一个客观且可复现的测试环境。在本次测试中,忆联UH812a凭借领先性能大幅降低数据加载耗时,这不仅验证了其作为AI数据底座的强大承载力,更彰显了忆联在高端企业级存储领域的技术实力。
测试软硬件环境
|
软件环境 |
软件/部件名称 |
版本号/型号 |
备注 |
|
|
umtool |
1.0.2.0-4 |
/ |
|
|
sysstat |
10.0.0 |
包含iostat,mpstat,sar |
|
|
ollama |
0.9.6 |
/ |
|
|
CUDA |
12.8 |
Driver Version: 570.124.06 |
|
|
OS |
CentOS Linux release 8.5.2111 |
/ |
|
硬件环境 |
CPU |
Intel(R) Xeon(R) Platinum 8358P CPU*2 @2.60GHz |
/ |
|
|
内存 |
DDR4 32 GB*16 |
共计512GB |
|
|
网卡 |
BCM57414 NetXtreme-E 10Gb/25Gb RDMA Ethernet Controller |
/ |
|
|
存储 |
系统盘:M.2 NVMe SSD 960GB 数据盘:Union memory UH812a 7.68T |
1、 数据盘通过PCIe Gen5转接卡连接 2、 盘片通过额外500W电源供电 |
|
|
转接卡 |
PCIe Gen5转接卡PCI5-AD-x16HI-BG5 |
连接1块数据盘 |
|
|
额定电源 |
500W额定电源 |
用于数据盘供电 |
|
|
显卡 |
NVIDIA Corporation GA100GL*8 |
显存共计192GB(8*24GB) |
测试组网规划
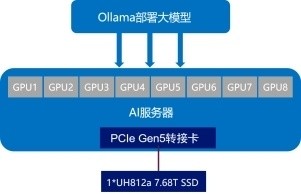
图1:测试组网规划图
测试步骤
● 步骤1:将待测SSD格式化为ext4文件系统,并挂载至指定目录。
● 步骤2:将准备好的离线大模型数据复制到SSD挂载的目录。
● 步骤3:清空内存,启动Ollama服务,执行模型加载命令,将目标从SSD加载至显存,并记录加载耗时。该步骤重复执行3次,取算术平均值作为最终测试结果。
测试结果
DeepSeek-R1系列模型加载性能测试
DeepSeek-R1作为业界主流的高性能开源模型,其参数规模从1.5B至671B不等,覆盖了从轻量级到千亿级的不同应用场景。该类模型的加载过程具有典型的随机读取特征,对存储设备抓取分散权重文件的IOPS性能提出了极高要求。本次测试覆盖了7B(小规模)、70B(中等规模)及671B(大规模)三个版本。
结果表明,忆联UH812a在Ollama平台上的模型加载表现全面优于竞品:
● Ollama加载DeepSeek-R1:671B模型:基于UH812a的平均耗时较竞品A降低48%;
● Ollama加载DeepSeek-R1:70B模型:基于UH812a的平均耗时较竞品A降低36%;
● Ollama加载DeepSeek-R1:7B模型:基于UH812a的平均耗时较竞品A降低21%。
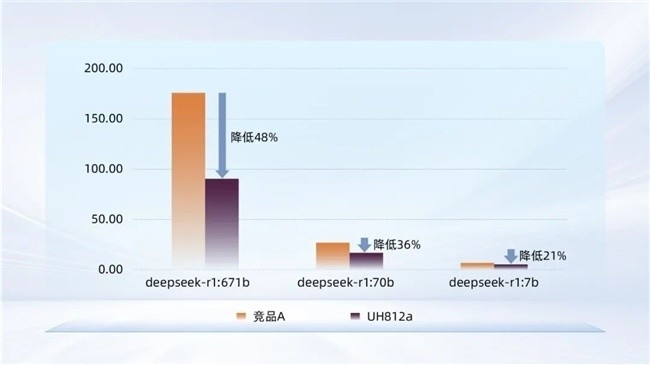
图2:Ollama加载DeepSeek-R1模型平均耗时(s)对比
DeepSeek-R1系列模型测试证明,忆联UH812a凭借卓越的随机读取性能,从容应对复杂推理模型的极端I/O挑战,它将高负载场景下的存储压力,转化为算力资源的充分释放与即时可用,为企业筑牢AI数据底座。
Qwen3系列模型加载性能测试
Qwen3作为阿里通义千问开源模型,其参数规格覆盖0.6B至235B。当加载32B、235B等较大规模模型时,海量大文件权重的高效调取对存储设备的顺序读取带宽提出了严苛要求。本次测试覆盖了8B及235B两个典型版本。
结果显示,忆联 UH812a在Ollama平台上的加载表现全面优于竞品A:
● Ollama加载Qwen3:235B模型:基于UH812a的平均耗时较竞品A降低40%;
● Ollama加载Qwen3:8B模型:基于UH812a的平均加载耗时较竞品A降低20%。
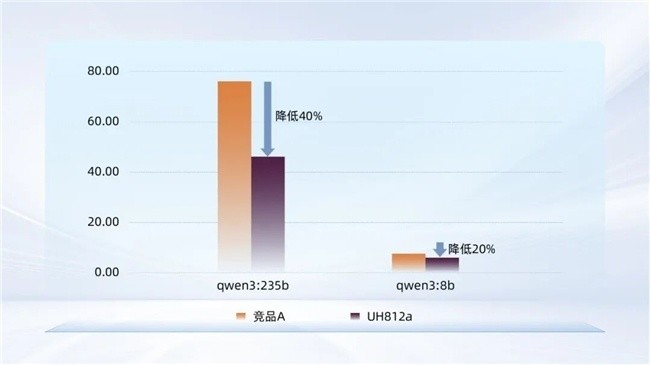
图3:Ollama加载Qwen3模型平均耗时(s)对比
Qwen3系列模型载入测试表明,忆联UH812a凭借卓越的顺序读写性能,从容应对大容量、高带宽工作负载,为企业级大规模AI应用提供稳定、敏捷的存储层支撑。
Llama3.1-405B超大规模模型加载性能测试
Llama3.1是Meta推出的旗舰级开源大模型,其405B超大规模版本对存储系统的容量支撑与高速读取能力提出了极致要求。本次在Ollama平台上聚焦该模型进行实测。
结果显示,使用UH812a的Ollama加载Llama3.1:405B模型的平均耗时较竞品低47%,展现出处理超大规模文件高效调取的卓越能力。这一领先优势源于UH812a的技术底座:PCIe 5.0接口带来的超高带宽,结合自主研发主控的高效调度算法,充分释放了Ollama框架在模型加载阶段的I/O潜力。
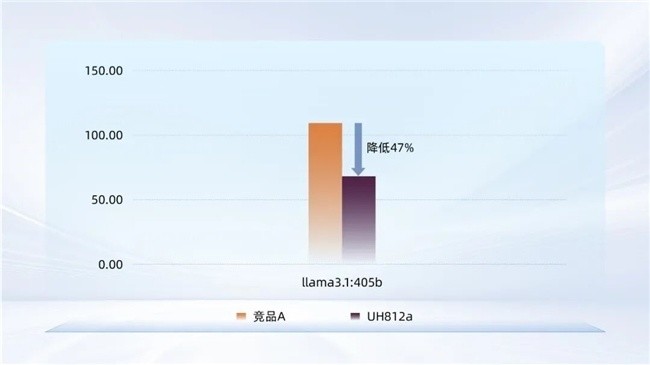
图4:Ollama加载Llama3.1模型平均耗时(s)对比
基于Ollama的深度测试表明,忆联UH812a能够充分满足从轻量级验证到大规模生产部署的全场景AI负载。作为突破模型加载I/O瓶颈、加速智能算力释放的关键一环,UH812a彰显了其在企业AI基础设施中的核心价值与领先地位。
面对AI模型参数规模的指数级增长与应用场景向实时化、边缘化的持续演进,忆联将以更优存力、更高标准,携手产业伙伴共同应对超大规模训练、实时推理与联邦学习等前沿挑战,为人工智能的下一阶段突破筑牢数据基石,让存力成为驱动智能未来的算力动脉。
26-03-05
26-03-04
26-03-04
26-03-03
26-03-01
26-02-27
26-02-26
26-02-26
26-02-26
26-02-24
每日投票数据[05:30]自动清零
版权所有 @2010-2012 财富投资网(银投网) 沪ICP备15014470号-14
投资有风险,入市须谨慎!



